网站SEO如何正确使用robots.txt
很多时候,您会发现网站会引用了一个名为robots.txt的文件,您可以使用该文件来实现搜索引擎索引和爬行方面的不同目标,告知搜索引擎是否应抓取您的网页。
robots.txt是一种遵循机器人(搜索引擎蜘蛛/爬虫)排除标准的纯文本文件,通过一条或多条规则,可以禁止或允许所有或指定搜索引擎机器人程序,抓取robots.txt文件所在域或子域上的指定目录或文件路径。除非您在robots.txt文件中另行指定,否则所有目录和文件均默认允许抓取。
百度搜索资源平台专门针对robots.txt文件的使用有一些说明,并且告诉您什么是robots.txt文件?、robots.txt文件的格式、robots.txt文件用法举例。关于robots.txt的规则、协议、使用方法,也可以点击链接查看。
使用说明
1.robots.txt可以告诉百度您网站的哪些页面可以被抓取,哪些页面不可以被抓取。
2. 您可以通过Robots工具来创建、校验、更新您的robots.txt文件,或查看您网站robots.txt文件在百度生效的情况。
3. Robots工具目前支持48k的文件内容检测,请保证您的robots.txt文件不要过大,目录最长不超过250个字符。
4. 如需检测未验证站点的robots设置,请点击此处进行检测。
还提供了一个“检测并更新”的按钮,如果你点击使用这个工具,百度会给出一些提示,如果无法检测到robots.txt文件:
您的服务器配置有误
百度暂时无法连接您的服务器,请检查服务器的设置,确保您网站的服务器能被正常访问。错误码:
如果工具检测到robots.txt文件:
您的Robots文件已生效

如果您担心robots.txt文件失误把本该让搜索引擎蜘蛛爬取的页面阻止了,百度还提供了检测URL是否被阻止的功能……,不过,百度的检测似乎并不严谨。
您还可以输入域名进行检测,地址:https://ziyuan.baidu.com/robots/intro,您可以使用这个功能测试品牌网站或竞争对手网站的robots.txt是如何设置的。
请注意,robots.txt并不是每个网站的强制要求。
如果您的网站没有robots.txt文件,也完全没问题。您无需太担心,没有robots.txt文件不会以任何方式损害您的网站。网站使用robots.txt文件对搜索引擎来说是友好的,因为它允许网站与搜索引擎蜘蛛通信并给他们一些指示。但是,没有robots.txt文件并不被认为是坏事或缺点。
您的网站需要robots.txt文件吗?
有几个问题值得思考:
- 您是否想对搜索引擎隐藏网站的某些部分,并且不希望搜索引擎在搜索结果页面上显示这些页面或部分的内容?
- 您想禁止特定搜索引擎抓取您网站的内容吗?例如,出于某种原因,您不希望360搜索索引并抓取您的网站内容?
- 您想限制搜索引擎对您网站上的图像内容进行爬网和索引吗?
- 您的网站是否有很大一部分正在进行临时维护,并且您希望搜索引擎暂时不要抓取该特定部分?
- 您想限制搜索引擎抓取您网站上的特定文件类型吗?例如,您的网站有很多PDF文档,您不想向公众披露这些文档,并且您希望这些URL不显示在搜索结果中?但是,您确实希望在搜索时显示其他页面,只是您不希望仅对PDF文件进行爬取或索引?
如果上述任何一个问题的答案肯定的 ,则您需要将robots.txt文件放置在您的网站或域名的根目录。如果上述所有问题的答案都是否定的 ,则您不需要robots.txt文件,可以安全地忽略它。
重复强调一下并请注意,您的网站上没有robots.txt文件不会以任何方式损害您的网站。
但是,拥有robots.txt文件并对其进行错误配置或放入一些您不理解的代码可能会损害您的网站。您必须知道您正在使用robots.txt文件做什么。
如果配置错误,则错误配置的robots.txt文件可能会对您的网站造成严重损坏,尽管可以通过更改robots.txt文件中的代码并将其替换为正确的代码来修复该损坏。
User-agent: *
Disallow: /
注意上面这两行代码,它会阻止所有搜索引擎访问您网站的内容。您网站的页面会突然从搜索引擎结果中消失,并且您将看不到任何流量进入。这对您的在线业务来说可能是一场彻底的灾难,因此请小心使用robots.txt文件。
注意robots.txt文件的位置
需要注意的一件非常重要的事情是,无论您的网站安装在哪个目录中,robots.txt文件始终放置在您域名的根目录下。
我们以前了解过htaccess文件,该文件也是放在目录下的,它不仅可以放在根目录,也可以放在根目录下的子目录中,例如admin目录,但是,不要想当然,robots.txt和htaccess文件不同,robots.txt只能放在根目录下。
例如,本网站的域名根目录是https://seo.lichil.com,seo知识放在子目录/seo/,后面,可能还要添加一个问题专栏放在子目录/faq/。
但整个域只有一个robots.txt文件,没有专门针对某个目录的robots.txt文件。
robots.txt文件将用于域https://seo.lichil.com,而不是用于目录或任何其他文件夹。robots.txt文件与域名相关联,而不是与单个文件夹、目录或子域相关联。无论网站安装在域名中的哪个位置,robots.txt文件始终放置在域名的根目录下。
前面,我们使用百度检测robots.txt的工具进行了检测,可能有些小小的意外,在检测/admin/是否被拦截的时候,并没有显示“已拦截”,以至于怀疑文件内容有错误。
这里,使用谷歌robots.txt测试工具再次尝试。
工具地址:
https://www.google.com/webmasters/tools/robots-testing-tool?utm_source=support.google.com/webmasters/&utm_medium=referral&utm_campaign=+6062598&siteUrl=https://seo.lichil.com/
https://www.google.com/webmasters/tools/robots-testing-tool
由于工具URL可能由于网络原因无法打开,所以此处没有加超链接,第一个URL有带有域名参数,您可以使用第二个URL,如果您还没有在谷歌的search console里面添加设置您的域名,打开时可能需要设置域名后才能正常使用。
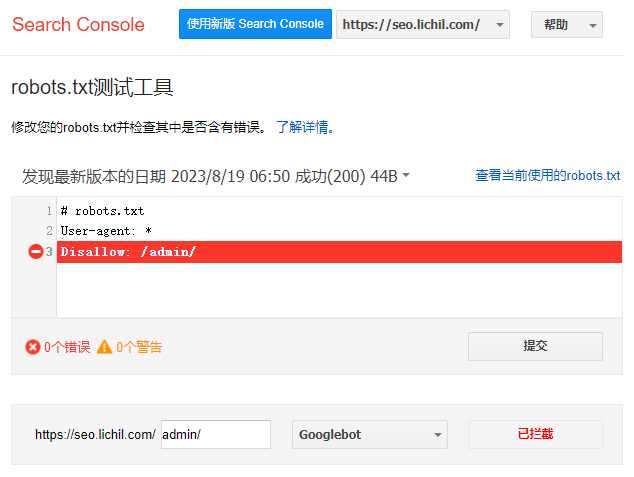
该工具将测试您的robots.txt文件并显示错误和警告,这是确定您放入robots.txt文件中的代码是否包含错误的好方法。
如上图所示,检测/admin/目录时,会显示“已拦截”,并且robots.txt文件里相对应的指令行被标为红底白字。
该页面还显示了谷歌所有的蜘蛛:Googlebot、Googlebot-News、Googlebot-Image、Googlebot-Video、Googlebot-Mobile、Mediapartners-Google、Adsbot-Google。
请注意,您放入robots.txt文件中的代码只是一个指令,它无法在您的网站上强制执行搜索引擎爬虫的行为,这取决于搜索引擎爬虫程序是否满足您的请求。在某些情况下,您可能已阻止robots.txt中的特定文件,但它会继续出现在搜索引擎中,因为存在指向该页面的外部链接,或者搜索引擎爬虫程序通过其他方式发现该内容并且它将继续出现显示在搜索结果中,无论您是否在robots.txt文件中阻止。
robots.txt文件支持通配符“*”和“$”,如果您不想像上面那样,把后台目录admin暴露在搜索引擎结果页面,也不想用户通过访问robots.txt文件获取后台目录,可以使用通配符来解决这个问题。
例如
User-agent: *
Disallow: /admin*/
如果您了正则表达式,应该很容易明白/admin*/匹配哪些目录,例如admin、admina、adminbc等,* 表示0个或多个任何有效字符。如果您想隐藏后台目录,建议不要直接使用admin命名,例如可以使用adminabcdefg命名,或者是其它名称。
请注意,如果您的网站有其它包含“admin”的目录,例如“admins"目录,也将会被拦截。所以如果您使用了通配符,应该特别注意网站目录的命名。
当然,这并不是唯一的方法,使用meta name="robots"元标签也可以禁止搜索引擎索引,这样不用再robots.txt里面暴露任何关于后台目录的信息。
例如:
<meta name="robots" content="noindex,nofollow">
隐藏后台目录并不是解决后台安全的最终方案,最终方案应该是后台的登录安全。
